Understanding key metrics for ragas
Motivation
In my article, Evaluating ragas: A framework for RAG pipelines, I explored the workings of ragas and the metrics it emphasizes. This piece offers a deeper examination of those metrics.
Performance Metrics
ragas evaluates RAG pipeline’s performance using the following dimensions:
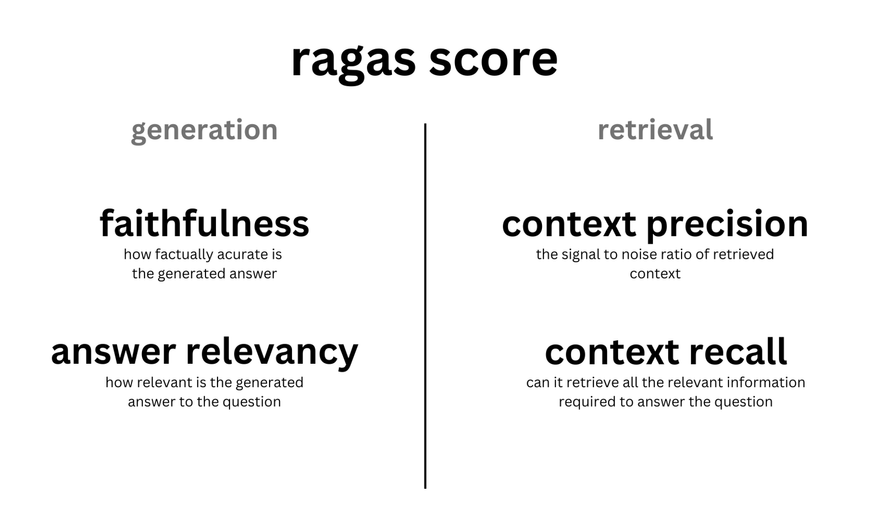
Faithfulness: Ensures the generated answer’s consistency with the given context. Penalties are given for claims not deduced from the context. Calculated using the answer and retrieved context.
Context Relevancy: Assesses the relevance of retrieved contexts to the question. Redundant information in the context is penalized. Calculated from the question and retrieved context.
Context Recall: Evaluates the recall of the retrieved context using the annotated answer as ground truth. Calculated using the ground truth and retrieved context.
Answer Relevancy: Measures how directly a response addresses a given question or context, without considering factuality. Redundant or incomplete answers are penalized. Calculated from the question and answer.
Aspect Critiques: Judges the submission against predefined aspects like harmlessness and correctness. Custom aspects can also be defined. The output is binary. Calculated from the answer.
The overall ragas_score is derived from the harmonic mean of these individual metric scores.
Metrics for retrievals
Context Relevancy
Summary
The code I checked is here.
The primary objective of this code is to assess the relevance of sentences within a context to a specific question. This is achieved by:
Prompt Generation: For each question-context pair, prompts are generated using the CONTEXT_RELEVANCE template.
CONTEXT_RELEVANCE = HumanMessagePromptTemplate.from_template( """\ Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you're not allowed to make any changes to sentences from given context. question:{question} context:\n{context} candidate sentences:\n""" # noqa: E501 )Response Generation: The prompts are fed to a model (likely a language model) to produce responses, which should be relevant sentences from the context.
Scoring Responses: The code evaluates the model’s responses for relevance to the context. For each context, the model might yield multiple responses, especially if strictness exceeds 1. These responses are then scored based on their overlap with the context and their consistency if multiple responses exist.
The code leverages various tools and libraries, such as BERT-based models and the Jaccard similarity metric. The central interface for this functionality is the ContextRelevancy class, instantiated at the module’s end.
Key Classes and Methods
ContextRelevancy: Contains the scoring mechanism. It’s crucial to also understand theSentenceAgreementclass, which plays a vital role in scoring.SentenceAgreement: Offers two methods to measure the similarity or “agreement” between two paragraphs:bert_score: Tokenizes paragraphs into sentences and computes pairwise similarity scores using a BERT-based cross-encoder.jaccard_score: Calculates the Jaccard similarity between two paragraphs’ sentences.
The code alternates between bert_score and jaccard_score based on the agreement_metric attribute of both classes. By default, ContextRelevancy uses bert_score.
ContextRelevancy is designed to extract sentences from a context that are relevant to a given question and perform self-consistency checks. The method starts by generating prompts for each question-context pair using the CONTEXT_RELEVANCE template.
Overlap score
This score represents the proportion of sentences from the context that the model deems relevant to the question. It’s an average of the overlap scores from all responses (n_response). By taking the average, the code accounts for potential variability in the model’s responses, especially if there are multiple responses due to a strictness value greater than 1. The overlap score essentially measures the model’s confidence in the relevance of the extracted sentences. A higher overlap score indicates that the model found more sentences in the context to be relevant to the question.
Agreement score
If there are multiple responses (n_response) for a single context (due to strictness > 1), the agreement score measures the consistency or similarity between these responses. A high agreement score indicates that the model’s responses are consistent across multiple samples, suggesting that the model is confident in its sentence extraction choices. If there’s only one response (strictness = 1), the agreement score is 1, indicating 100% consistency.
Final score
Multiplying the average overlap score with the agreement score provides a composite score that accounts for both the relevance of the extracted sentences and the consistency of the model’s responses. The product ensures that both factors are considered. For instance, if either the overlap or the agreement is low, the final score will be penalized.
Scoring Breakdown
scores = []
for context, n_response in zip(contexts, responses):
context = "\n".join(context)
overlap_scores = []
context_sents = sent_tokenize(context)
for output in n_response:
indices = (
output.split("\n")
if output.lower() != "insufficient information."
else []
)
score = min(len(indices) / len(context_sents), 1)
overlap_scores.append(score)
if self.strictness > 1:
agr_score = self.sent_agreement.evaluate(n_response)
else:
agr_score = 1
scores.append(agr_score * np.mean(overlap_scores))
- Tokenize the Context: The context is divided into individual sentences using the
sent_tokenizefunction, resulting in a list of sentences from the original context. - Calculate Overlap Scores:
- For each response in
n_response:- If the response is “insufficient information”, it indicates the model couldn’t identify any relevant sentences, leading to zero overlap.
- Otherwise, the response is split into individual sentences or indices.
- The overlap score for this response is the ratio of relevant sentences (from the response) to the total sentences in the context, capped at 1 (or 100%).
- The overlap scores for all responses are compiled into the
overlap_scoreslist.
- For each response in
- Calculate Agreement Score:
- If strictness exceeds 1, indicating multiple responses for the same context, the code evaluates the consistency of these responses using the
sent_agreement.evaluate(n_response)method, resulting in theagr_score. - For strictness of 1, with only one response, its self-consistency is 100%, setting
agr_scoreto 1.
- If strictness exceeds 1, indicating multiple responses for the same context, the code evaluates the consistency of these responses using the
- Final Score Calculation:
- The final score for a context is the product of:
- The average of all overlap scores (
np.mean(overlap_scores)) - The agreement score (
agr_score).
- The average of all overlap scores (
- The final score for a context is the product of:
This scoring process is iteratively applied to each context in the dataset. At the end, a list of scores is generated, each representing the relevance and consistency of the model’s responses for a specific context.
In summary, the scoring mechanism in the ContextRelevancy class evaluates the relevance and consistency of sentences extracted from a context to answer a given question. The score is a combination of how much of the context is deemed relevant and how consistent the model’s responses are across multiple samples.
Example
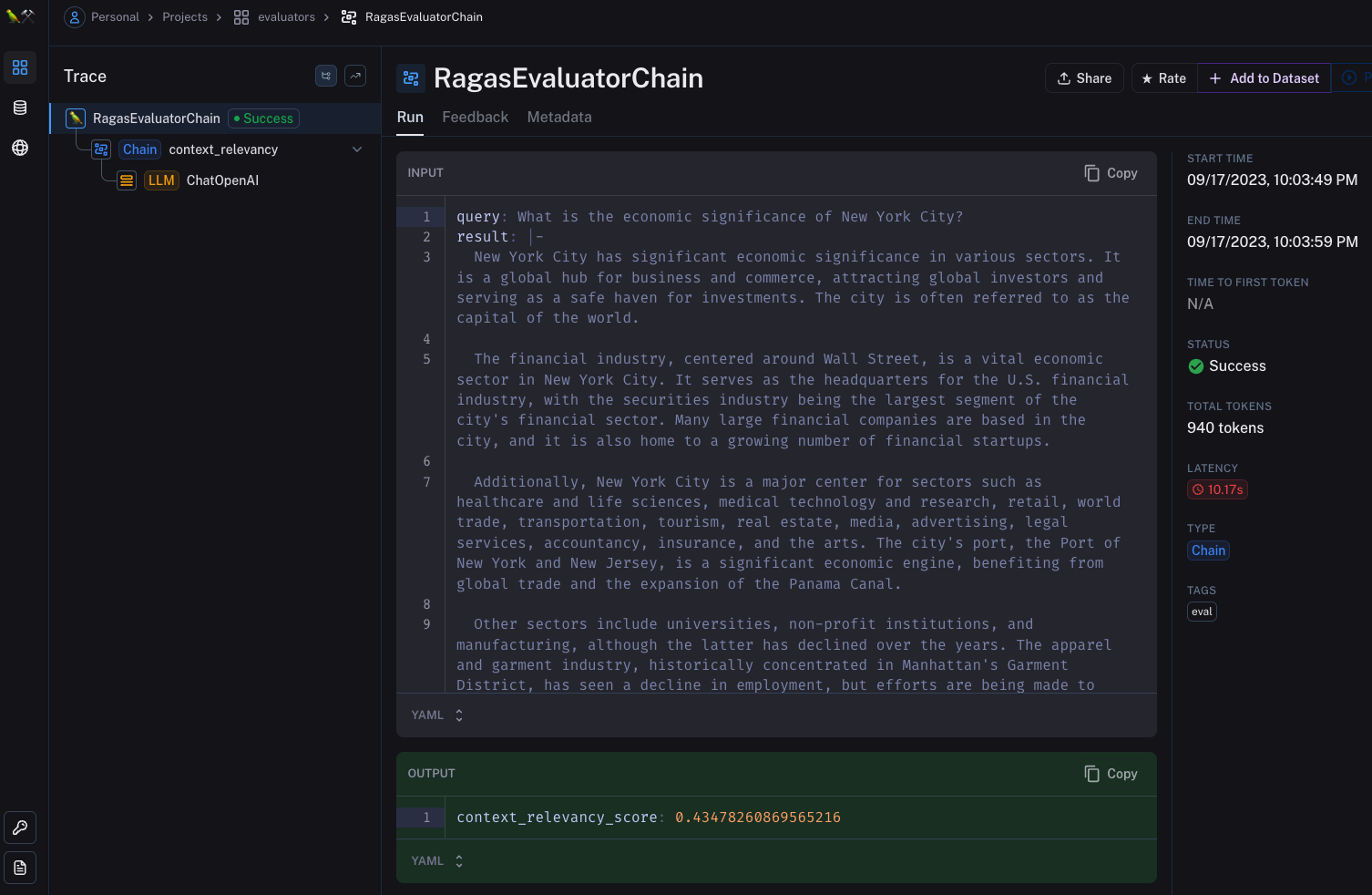
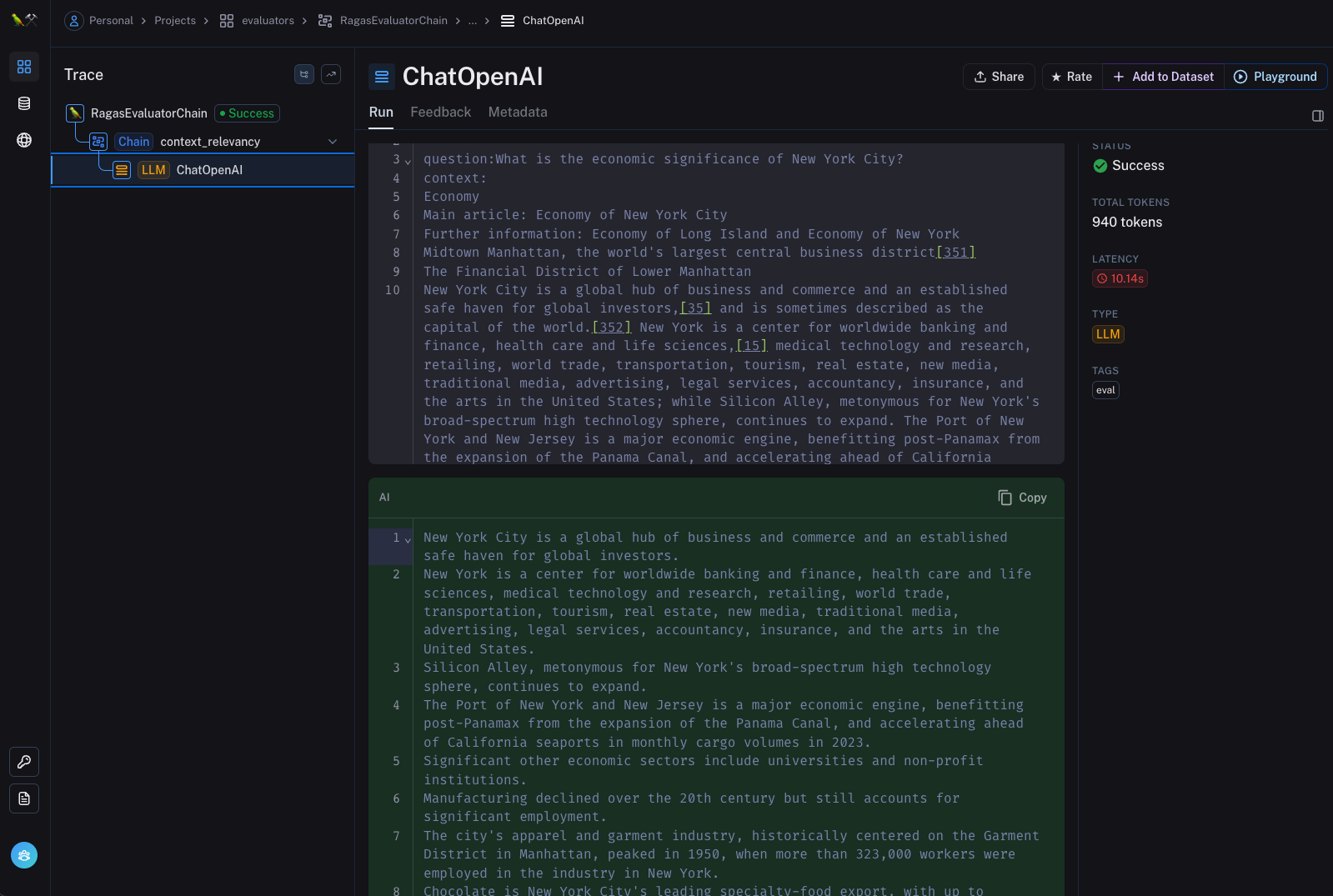
Context Recall
The code I checked is here.
The main goal of the code is to evaluate how well certain answers recall the context they are based on. To achieve this, the system generates prompts using the CONTEXT_RECALL_RA template. This template instructs a model to classify sentences in an answer based on a given context. The model’s response should indicate whether each sentence in the answer can be attributed to the context or not.
scores = []
for response in responses:
sentences = response[0].split("\n")
denom = len(sentences)
numerator = sum(
bool(sentence.find(verdict_token) != -1) for sentence in sentences
)
scores.append(numerator / denom)
For each response in responses:
- The response is split into individual sentences.
- denom is set to the total number of sentences in the response.
- numerator counts the number of sentences that contain the verdict_token (”[Attributed]“).
- The score for this response is calculated as the ratio of numerator to denom and appended to the scores list.
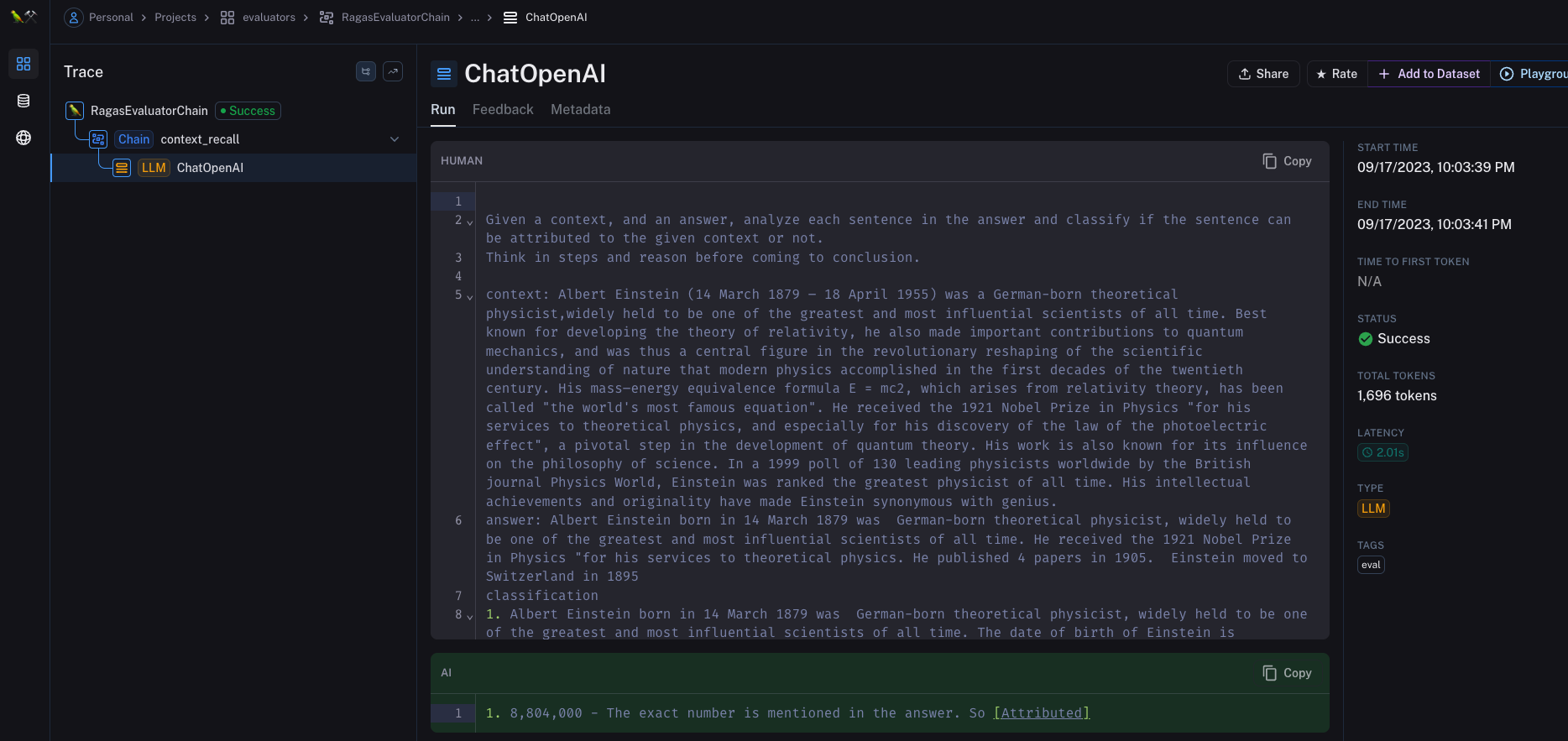
The verdict_token is set to the string [Attributed]. In the context of this code, sentences that contain the verdict_token are those that have been classified as being attributed to the given context. When we look at the CONTEXT_RECALL_RA template, there is an example classification:
classification
1. Albert Einstein born in 14 March 1879 was German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time. The date of birth of Einstein is mentioned clearly in the context. So [Attributed]
2. He published 4 papers in 1905. There is no mention about papers he wrote in given the context. So [Not Attributed]
In this example, sentences from the answer are classified as either [Attributed] or [Not Attributed] based on the context. The verdict_token serves as a marker to identify which sentences in the model’s response are considered to be correctly attributed to the given context. This mechanism enables the system to calculate scores for context recall.
The score for each response is determined by the proportion of sentences that are attributed to the context. If a sentence contains the verdict_token, it’s counted as a “true positive” (correctly attributed to the context). The score is then the ratio of these true positives to the total number of sentences in the response.
Example
Metrics for generations
Faithfulness
to be added
Answer Relevancy
to be added.
Aspect Critiques
to be added.