Evaluating ragas: A framework for RAG pipelines
TL;DR
ragas is a framework designed to assess the performance of Retrieval Augmented Generation (RAG) pipelines, a type of LLM application that uses external data to enhance its context. While there are tools to build RAG pipelines, evaluating their performance can be challenging. ragas offers tools rooted in recent research to evaluate LLM-generated text, providing insights into RAG pipeline performance. It can also be incorporated into CI/CD for ongoing performance checks.
Motivation
Assessing the output quality of LLM applications that use RAG, like chatbots and QA systems, is becoming a key focus for deploying these applications in production. I came across https://github.com/explodinggradients/ragas, which offers insights into evaluating LLM output quality using various metrics. This article explores ragas using a sample dataset and discusses the effectiveness of the metrics provided by the framework.
What is ragas?
According to https://github.com/explodinggradients/ragas
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
Note: Although the repository has inconsistencies in the use of “ragas” and “Ragas”, this article uses “ragas”.
Performance Metrics
ragas evaluates RAG pipeline’s performance using the following dimensions:
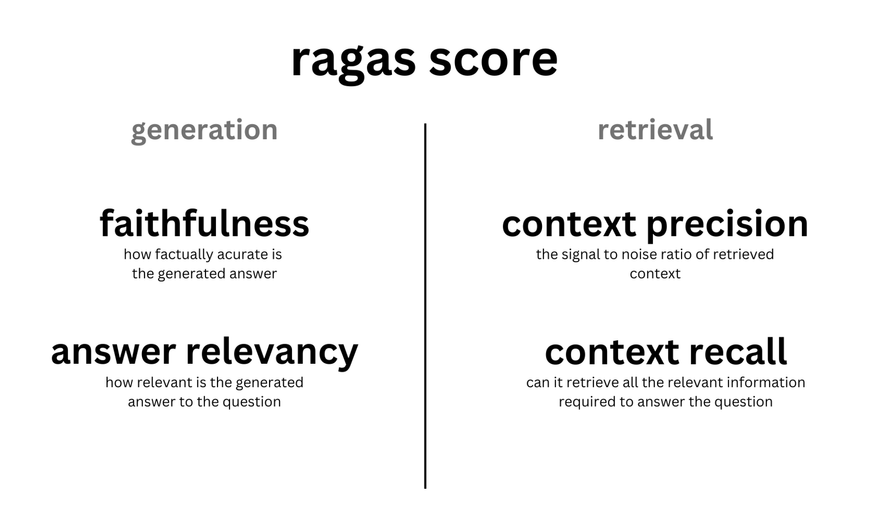
Faithfulness: Ensures the generated answer’s consistency with the given context. Penalties are given for claims not deduced from the context. Calculated using the answer and retrieved context.
Context Relevancy: Assesses the relevance of retrieved contexts to the question. Redundant information in the context is penalized. Calculated from the question and retrieved context.
Context Recall: Evaluates the recall of the retrieved context using the annotated answer as ground truth. Calculated using the ground truth and retrieved context.
Answer Relevancy: Measures how directly a response addresses a given question or context, without considering factuality. Redundant or incomplete answers are penalized. Calculated from the question and answer.
Aspect Critiques: Judges the submission against predefined aspects like harmlessness and correctness. Custom aspects can also be defined. The output is binary. Calculated from the answer.
The overall ragas_score is derived from the harmonic mean of these individual metric scores. I feel it makes sense to split performance metrics for retrieval and generation. See Understanding ragas and their key metrics for more details.
Experiment environment
This experiment uses ragas v0.0.14 and was executed on Google Colab.
Experiment code
Installation
!pip install ragas tiktoken
Configure OpenAI API key
Because ragas uses OpenAI by default produce metrics, we need to configure OPENAI_API_KEY.
import getpass
import os
openai_api_key = input('Enter your OpenAI API key:')
os.environ["OPENAI_API_KEY"] = openai_api_key
Load dataset
to work with ragas all you need are the following data
- question:
list[str]- These are the questions you RAG pipeline will be evaluated on. - answer:
list[str]- The answer generated from the RAG pipeline and give to the user. - contexts:
list[list[str]]- The contexts which where passed into the LLM to answer the question. ground_truths:
list[list[str]]- The ground truth answer to the questions.from pprint import pprint from datasets import load_dataset # See the data set on Hugging Face: # https://huggingface.co/datasets/explodinggradients/fiqa/viewer/ragas_eval/baseline?row=0 ds = load_dataset("explodinggradients/fiqa", "ragas_eval") # See Dataset API: # https://huggingface.co/docs/datasets/package_reference/main_classes print(f"Column names: {ds.column_names}") print(f"Shape: {ds.shape}") # See how to process dataset: # https://huggingface.co/docs/datasets/process print("Example:") pprint(ds['baseline'][0])
output
Column names: {'baseline': ['question', 'ground_truths', 'answer', 'contexts']}
Shape: {'baseline': (30, 4)}
Example:
{'answer': '\n'
'The best way to deposit a cheque issued to an associate in your '
'business into your business account is to open a business account '
'with the bank. You will need a state-issued "dba" certificate from '
"the county clerk's office as well as an Employer ID Number (EIN) "
'issued by the IRS. Once you have opened the business account, you '
'can have the associate sign the back of the cheque and deposit it '
'into the business account.',
'contexts': ['Just have the associate sign the back and then deposit it. '
"It's called a third party cheque and is perfectly legal. I "
"wouldn't be surprised if it has a longer hold period and, as "
"always, you don't get the money if the cheque doesn't clear. "
"Now, you may have problems if it's a large amount or you're not "
'very well known at the bank. In that case you can have the '
'associate go to the bank and endorse it in front of the teller '
"with some ID. You don't even technically have to be there. "
'Anybody can deposit money to your account if they have the '
'account number. He could also just deposit it in his account '
'and write a cheque to the business."I have checked with Bank of '
'America, and they say the ONLY way to cash (or deposit, or '
'otherwise get access to the funds represented by a check made '
'out to my business) is to open a business account. They tell me '
'this is a Federal regulation, and every bank will say the same '
'thing. To do this, I need a state-issued ""dba"" certificate '
"(from the county clerk's office) as well as an Employer ID "
'Number (EIN) issued by the IRS. AND their CHEAPEST business '
'banking account costs $15 / month. I think I can go to the bank '
'that the check is drawn upon, and they will cash it, assuming I '
'have documentation showing that I am the sole proprietor. But '
'I\'m not sure.... What a racket!!"When a business asks me to '
'make out a cheque to a person rather than the business name, I '
'take that as a red flag. Frankly it usually means that the '
"person doesn't want the money going through their business "
"account for some reason - probably tax evasion. I'm not saying "
'you are doing that, but it is a frequent issue. If the company '
'makes the cheque out to a person they may run the risk of being '
'party to fraud. Worse still they only have your word for it '
"that you actually own the company, and aren't ripping off your "
'employer by pocketing their payment. Even worse, when the '
'company is audited and finds that cheque, the person who wrote '
'it will have to justify and document why they made it out to '
"you or risk being charged with embezzlement. It's very much in "
'their interests to make the cheque out to the company they did '
'business with. Given that, you should really have an account in '
"the name of your business. It's going to make your life much "
'simpler in the long run.'],
'ground_truths': ['Have the check reissued to the proper payee.Just have the '
"associate sign the back and then deposit it. It's called "
"a third party cheque and is perfectly legal. I wouldn't "
'be surprised if it has a longer hold period and, as '
"always, you don't get the money if the cheque doesn't "
"clear. Now, you may have problems if it's a large amount "
"or you're not very well known at the bank. In that case "
'you can have the associate go to the bank and endorse it '
"in front of the teller with some ID. You don't even "
'technically have to be there. Anybody can deposit money '
'to your account if they have the account number. He could '
'also just deposit it in his account and write a cheque to '
'the business.'],
'question': 'How to deposit a cheque issued to an associate in my business '
'into my business account?'}
Import metrics
The available metrics are listed on docs/metrics.md. This experiment imports Faithfulness, ContextRelevancy, Context Recall, AnswerRelevancy, and AspectCritique.
from ragas.metrics import (
context_relevancy,
answer_relevancy,
faithfulness,
context_recall,
)
from ragas.metrics.critique import harmfulness
Run evaluation
from ragas import evaluate
result = evaluate(
ds["baseline"],
metrics=[
context_relevancy,
faithfulness,
answer_relevancy,
context_recall,
harmfulness,
],
)
result
output:
evaluating with [context_relevancy]
100%|██████████| 2/2 [02:37<00:00, 78.72s/it]
evaluating with [faithfulness]
100%|██████████| 2/2 [03:47<00:00, 113.94s/it]
evaluating with [answer_relevancy]
100%|██████████| 2/2 [00:32<00:00, 16.44s/it]
evaluating with [context_recall]
100%|██████████| 2/2 [04:54<00:00, 147.13s/it]
evaluating with [harmfulness]
100%|██████████| 2/2 [00:49<00:00, 24.96s/it]
{'ragas_score': 0.6655, 'context_relevancy': 0.6299, 'faithfulness': 0.7712, 'answer_relevancy': 0.9255, 'context_recall': 0.4889, 'harmfulness': 0.0000}
Result
For the readability, convert the result into Pandas Dataframe and list the first result.
df = result.to_pandas()
df1 = df.head(1)
# print(f"Quesiton: {df1.question}")
# print(f"Answer: {df1.answer}")
# print(f"Context: {df1.contexts}")
# print(f"Context: {df1.ground_truths}")
df1[[
"context_relevancy",
"faithfulness",
"answer_relevancy",
"context_recall",
"harmfulness",
]]
The final result is as follows:
| index | context_relevancy | faithfulness | answer_relevancy | context_recall | harmfulness |
|---|---|---|---|---|---|
| 0 | 0.47058823529411764 | 1.0 | 0.9767929501574013 | 0.1111111111111111 | 0 |
The above table only displays the first result. The cost we calculate for the dataset is around $1.
Result analysis
To be added.
LangSmith Result
Project top
Input/Output
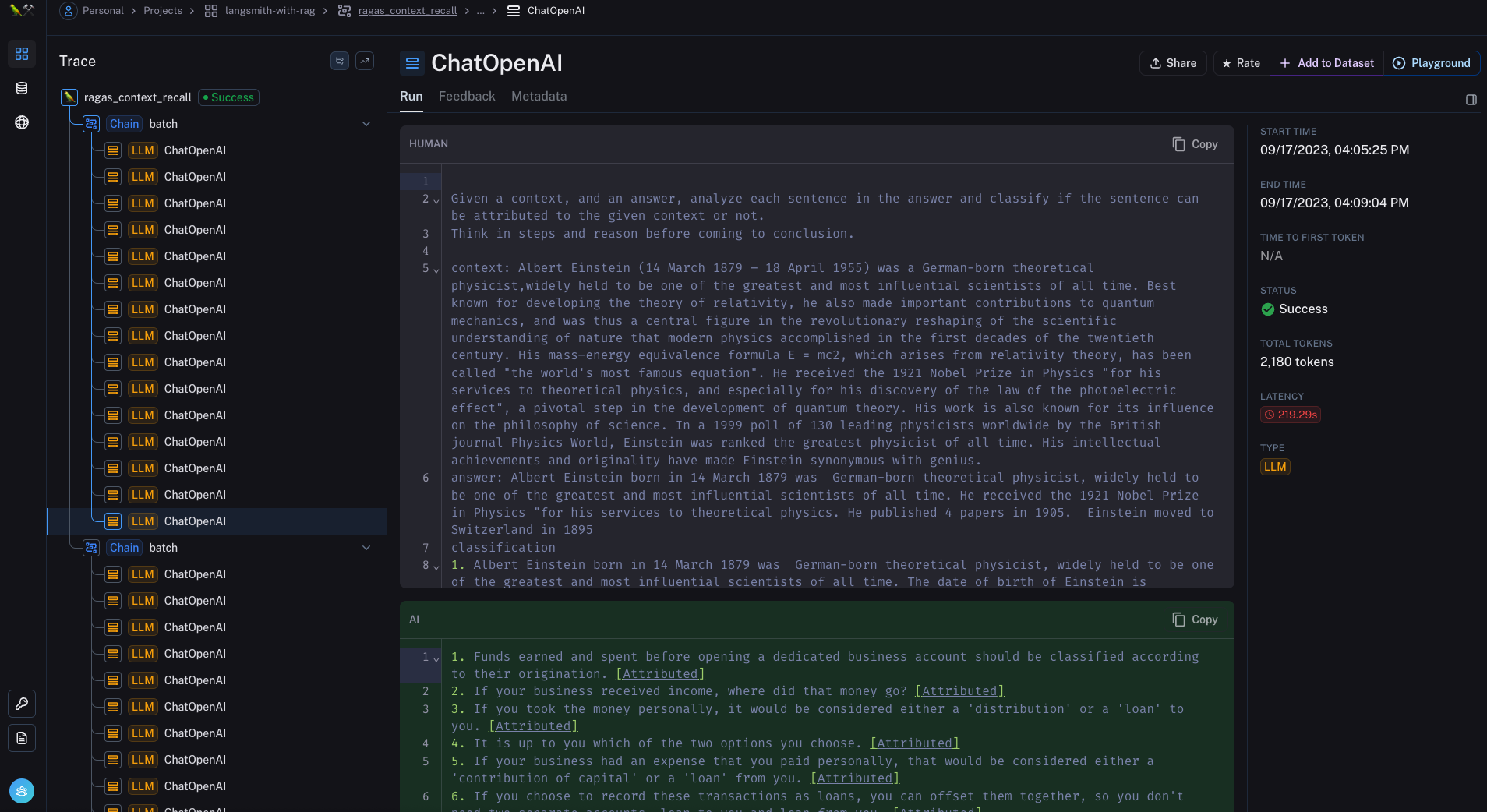
Feedback
Metadata
Discussion
According to the following materials, ragas has LangChain and LangSmith integrations with RagasEvaluatorChainto capture more tracing information on a feedback tab. I will check the integration with another article.
- Evaluating RAG pipelines with Ragas + LangSmith
- https://github.com/explodinggradients/ragas/blob/e194caa394475cf5aa877a7886f8b51e1a31a3e2/docs/integrations/langsmith.ipynb
- https://github.com/explodinggradients/ragas/blob/e194caa394475cf5aa877a7886f8b51e1a31a3e2/docs/integrations/langchain.ipynb
Disabling usage tracking on ragas
ragas sends metrics for tracking usage by default. If we want to disable usage-tracking, we need to set the RAGAS_DO_NOT_TRACK flag to true.